
Wenn es um KI-Chatbots geht, sprechen alle über Gemini Advanced und ChatGPT Plus. Diese beiden sind die großen Spieler auf dem Feld und jeder hat seine eigenen Stärken. In diesem Beitrag werfen wir einen Blick darauf, was jedes von ihnen zu bieten hat.
Ob Gemini Advanced oder ChatGPT Plus besser ist, hängt vom jeweiligen Anwendungsfall ab. Für unseren täglichen Gebrauch empfinden wir ChatGPT Plus derzeit noch überlegen. Gemini Advanced ist zwar schneller, aber der Output ist oft nicht konsistent.
Inhaltsverzeichnis
1) Test im Bereich Bilderstellung
Da wir inzwischen stark auf AI generierte Bilder setzen, ist ein wichtiges Entscheidungskriterium für uns, ob hochwertige Bilder erstellt werden können. Leider kann Gemini Advanced aktuell keine Bilder generieren. Hier das Ergebnis unseres Tests mit dem Prompt: Erstelle mir ein Bild von einem Roboter in der Wüste.
| Chat GPT 4 Plus | Gemini Advanced |
|---|---|
 |
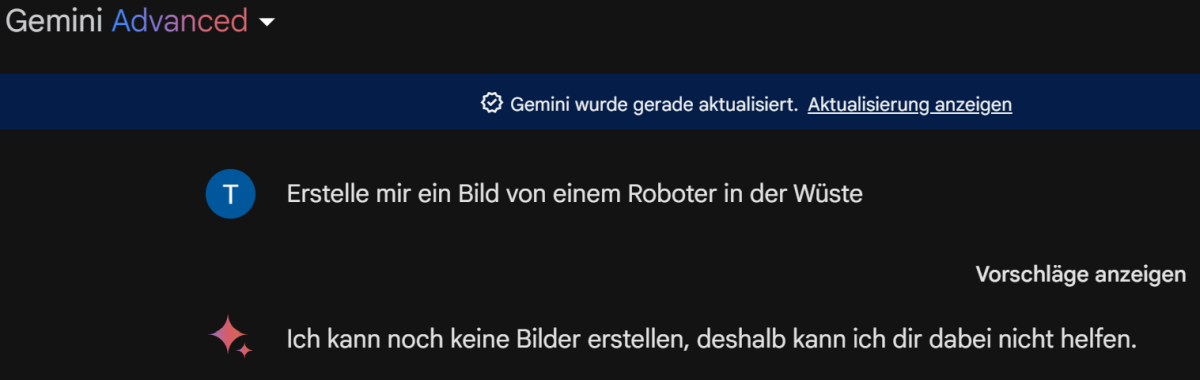 |
2. Artikel schreiben
Das war der Prompt: Schreibe mir einen ausführlichen Beitrag mit 1000 Wörtern zum Thema „Digitale Transformation“. Wähle selbst geeignete Unterüberschriften aus und gestalte den Beitrag mit strukturellen Elementen wie Bullet Point Listen und Tabellen. Wähle selbst die Abschnitte aus wo das Sinn macht. Mach immer nach 2 bis 3 Sätzen einen Absatz. Gib mir den gesamten Beitrag als html code damit ich ihn direkt in WordPress kopieren kann.
| Chat GPT Plus | Gemini Advanced | |
|---|---|---|
| Dauer für die Erstellung | 2:10 Minuten | 0:32 Minuten |
| Ergebnis | Schlecht | Schlecht |
| Textlänge | 416 Wörter | 325 Wörter |
|
|
|
| Fertigen Text ansehen | Link | Link |
Aus Interesse haben wir den gleichen Prompt auch noch mit GPT 3.5 ausprobiert. Das Ergebnis sehen Sie hier: Link . Die Textlänge war 484 Wörter. Insgesamt wohl das beste Ergebnis.
Preisvergleich
Wenn wir uns dem Preisvergleich zuwenden, ist es interessant festzustellen, dass Gemini Advanced und ChatGPT Plus mit ihren aktuellen Abonnementpreisen nahezu gleichauf liegen.
Gemini Advanced wird für 21,99 Euro angeboten, während ChatGPT Plus auf dem Markt für 23,80 Dollar, umgerechnet etwa 21,91 Euro bei aktuellem Wechselkurs, erhältlich ist. Dies zeigt, dass die Kosten für die beiden KI Modelle bemerkenswert ähnlich sind.
Leistungsvergleich von KI-Modellen in Schlüsselkategorien
Im Folgenden betrachten wir einen direkten Vergleich der Leistungsfähigkeit von führenden KI-Modellen in diversen Bewertungskriterien. Diese Tabelle veranschaulicht, wie Gemini Pro, ChatGPT-3.5, Gemini Ultra und ChatGPT-4 in unterschiedlichen Disziplinen abschneiden.
Jedes Modell wurde in einer Reihe von Benchmarks getestet, um ihre Fähigkeiten in Sprachverständnis, arithmetischem Denken, Codegenerierung und weiteren anspruchsvollen Bereichen zu evaluieren.
| Gemini Pro | ChatGPT-3.5 | Gemini Ultra | ChatGPT-4 | |
|---|---|---|---|---|
| Sprache | 79,13% (MMLU) | 70% (MMLU) | 90,0% (MMLU) | 86,4% (MMLU) |
| Arithmetisches Denken | 86,5% (GSM8K) | 57,1% (GSM8K) | 94,4% (GSM8K) | 92% (GSM8K) |
| Codegenerierung | 67,7% (HumanEval) | 48,1% (HumanEval) | 74,4% (HumanEval) | 67% (HumanEval) |
| Mathematik | 32,6% (MATH) | 34,1% (MATH) | 53,2% (MATH) | 52,9% (MATH) |
| Bildverarbeitung (Pixel) | 59,4% (MMMU) | 56,8% (MMMU) | – | – |
| VQAV2 | 77,8% | 77,2% | – | – |
| TextVQA | 82,3% | 78% | – | – |
| DOCVQA | 90,9% | 88,4% | – | – |
| Videoverarbeitung (Pixel) | 53% (MathVista) | 49,9% (MathVista) | – | – |
| VATEX | 62,7% (CIDEr) | 56% (CIDEr) | – | – |
| CoVoST 2 (BLEU) | 40,1% | 29,1% | – | – |
| FLEURS (Wortfehlerrate) | 10% | 17,6% | – | – |
Datenquelle: Link
Es folgt eine Erklärung der verschiedenen Kriterien:
- Sprache: Dieser Test misst die Fähigkeit des Modells, Fragen zu 57 verschiedenen Themen zu verstehen und zu beantworten. Der MMLU-Benchmark (Massive Multitask Language Understanding) wird verwendet, um die Leistung zu bewerten.
- Arithmetisches Denken: Dieser Test misst die Fähigkeit des Modells, mathematische Probleme der Grundschule zu lösen. Der GSM8K-Benchmark (General Scholastic Mathematics 8K) wird verwendet, um die Leistung zu bewerten.
- Codegenerierung: Dieser Test misst die Fähigkeit des Modells, Python-Code zu generieren. Die HumanEval-Benchmarks werden verwendet, um die Leistung zu bewerten.
- Mathematik: Dieser Test misst die Fähigkeit des Modells, komplexere mathematische Probleme zu lösen, einschließlich Algebra und Geometrie.
- Bildverarbeitung (Pixel): Dieser Test misst die Fähigkeit des Modells, Bilder auf Pixelebene zu verstehen und zu interpretieren. Der MMMU-Benchmark (Multi-discipline College-level Reasoning) wird verwendet, um die Leistung zu bewerten.
- VQAV2: Dieser Test misst die Fähigkeit des Modells, die Qualität von Bildern zu beurteilen.
- TextVQA: Dieser Test misst die Fähigkeit des Modells, Fragen zu beantworten, die sich auf den Inhalt von Bildern beziehen.
- DOCVQA: Dieser Test misst die Fähigkeit des Modells, Fragen zu beantworten, die sich auf den Inhalt von Dokumenten beziehen.
- Videoverarbeitung (Pixel): Dieser Test misst die Fähigkeit des Modells, Videos auf Pixelebene zu verstehen und zu interpretieren.
- VATEX: Dieser Test misst die Fähigkeit des Modells, Videos zu beschreiben und zu betiteln.
- CoVoST 2 (BLEU): Dieser Test misst die Fähigkeit des Modells, Sprache automatisch zu übersetzen. Der BLEU-Score (Bilingual Evaluation Understudy) wird verwendet, um die Leistung zu bewerten.
- FLEURS (Wortfehlerrate): Dieser Test misst die Fähigkeit des Modells, Sprache automatisch zu erkennen. Die Wortfehlerrate wird verwendet, um die Leistung zu bewerten.


